About this Handbook
This Handbook is meant to contain a comprehensive description of how Dataland works and the practices with which Dataland is built.
This is necessarily a living document, as both Dataland itself and the way Dataland is built is constantly changing. It is structured as a mdBook, and lives in the dataland-engineering-handbook repo. PRs to improve the Handbook are one of the most impactful things we do, and a wonderfully levered use of time.
Core engineering values
Our core engineering values are the values that we internalize deeply and guide our day to day decision making.
Our choice of values is what sets us apart as a team, in contrast with other teams that embody a different set of values. While there are many good values in the world, trying to uphold them all is equivalent to upholding none.
We have 4 core engineering values that we uniquely uphold over all others:
Wisdom
Find the right frame.
Wisdom is about finding the right objective function under each circumstance and choosing a reasonably maximal solution.
The first part is much more important to get right than the second, because it is better to be approximately right than precisely wrong.
Reasoning about each circumstance from first principles and figuring out the right lens with which to view it is the most important activity we engage in.
Relentless User Focus
The only thing that matters in the end.
There is one objective function that reigns above all others, and that is the product experience for the end user.
How much we improve their working lives, how much simplicity & power they gain when using our product, how much delight it brings to them — these are the measures by which we ultimately live or die.
In any circumstance where there is a user-maximizing decision, there is no choice at all.
Craftsmanship
Get it right.
This codebase is our home. We spend more time inhabiting this mental space than any other space in our lives.
If we make it good, we will love coming back to it day after day. If we love coming back to it day after day, we will almost certainly deliver outsized value for our users. It will also make our own everyday experience that much more fun and joyful.
If we let it fall apart, we will hate inhabiting the one space we inhabit most. We will achieve only average results and quickly become irrelevant.
Far from being superfluous, craftsmanship is critical to the longevity of our success.
Intellectual Rigor
Achieve understanding.
We care deeply about achieving understanding in what we do.
We put in the time to read the source code of libraries and services we use and getting to know how they actually work.
We put in the time to read papers and blogs to understand the state of the art and to learn from how leading practitioners think about their fields.
We put in the time to fully articulate our designs and implementations, putting their claims to the test with code (tests, benchmarks) and conversation (dialogue, RFCs).
All of this time is time wonderfully spent.
At the margin it might seem unclear how a deep level of understanding translates to an immediate unit of output. But understanding is a compounding force. Over time, our understanding becomes an unsurpassable moat, giving us the ability to do things that no one else can do.
Onboarding guide
We've prepared the following resources to help you get up to speed:
Reading list
The goal is for each reading list to contain sufficient information such that after reading it, an exprienced engineer is ready to start making meaningful contributions to that area of the product in a way that's aligned with the practices of the team.
Everyone
Read our Core Engineering Values and spend time to understand them.
Backend / Systems
Complete the entirety of the Rust Guide, or achieve a comparable level of fluency in Rust.
Read through the Protocol Buffers Guide, especially the section on Encoding. Given that we deal with the data plane, it's important that we actually understand how the bits are laid out — not all ways of expressing the same semantic structure is equivalent, some are much more efficient than others.
Read Lampson's classic guide on system design: https://bwlampson.site/33-Hints/Acrobat.pdf
Frontend / UI
Complete the entirety of the React & Redux Guide, or achieve a comparable level of fluency in React and Redux.
Read our Frontend Philosophy.
Infra
Dev setup
Mac & Linux
-
On Mac:
brew install git just sqlx-cli mdbook postgresql shellcheck tokei ripgrep bat exa procs fd sd cue-lang/tap/cue npm install -g zxOn Linux:
cargo install sqlx-cli mdbook just tokei ripgrep bat exa procs fd sd sudo apt-get install git shellcheck postgresql brew install cue-lang/tap/cue npm install -g zx -
Install mkcert: https://github.com/FiloSottile/mkcert
- Make sure to run
mkcert -installto install the dev CA, but no need manually generate any certs.
- Make sure to run
-
Install GitHub Desktop: https://desktop.github.com/
-
Install Node
-
Install nvm: https://github.com/nvm-sh/nvm
-
Install specific versions of Node and NPM:
nvm install v16.14.2 nvm alias default v16.14.2 npm install -g npm@8.5.5 node --version && npm --version
-
-
Install Rust
-
Install rustup: https://www.rust-lang.org/tools/install
-
Install components:
rustup component add rustc cargo rust-std rustfmt clippy rust-docs -
Check that Rust is >=1.62.0:
rustc --version
-
-
Install the Protocol Buffers compiler:
-
Manually download the binary (brew and apt for protoc are pretty out of date):
cd ~ # This URL is for Intel Macs - for other machines check https://github.com/protocolbuffers/protobuf/releases curl -o ~/protoc.tar.gz -L https://github.com/protocolbuffers/protobuf/releases/download/v21.1/protoc-21.1-osx-x86_64.zip mkdir -p ~/protoc unzip protoc.tar.gz -d ~/protoc rm ~/protoc.tar.gz -
Add the following to your
.bash_profile/.zshenv/ etc:export PATH="$HOME/protoc/bin:$PATH" # meant to be consumed by the `prost-build` Rust crate: export PROTOC="$HOME/protoc/bin/protoc" export PROTOC_INCLUDE="$HOME/protoc/include" -
Check that protoc is >=3.21.1:
protoc --version
-
-
Install Docker Desktop for Mac: https://docs.docker.com/docker-for-mac/install/
-
Check that Docker is >=20.10.11 and Docker Compose is >=1.29.2:
docker --version && docker-compose --version -
This step is not needed for Linux, as resources are already unlimited.
Increase the system resources granted to Docker. This is necessary because compiling release binaries in Rust is very resource-intensive — especially compiling & optimizing a large number of dependencies. Example configuration:
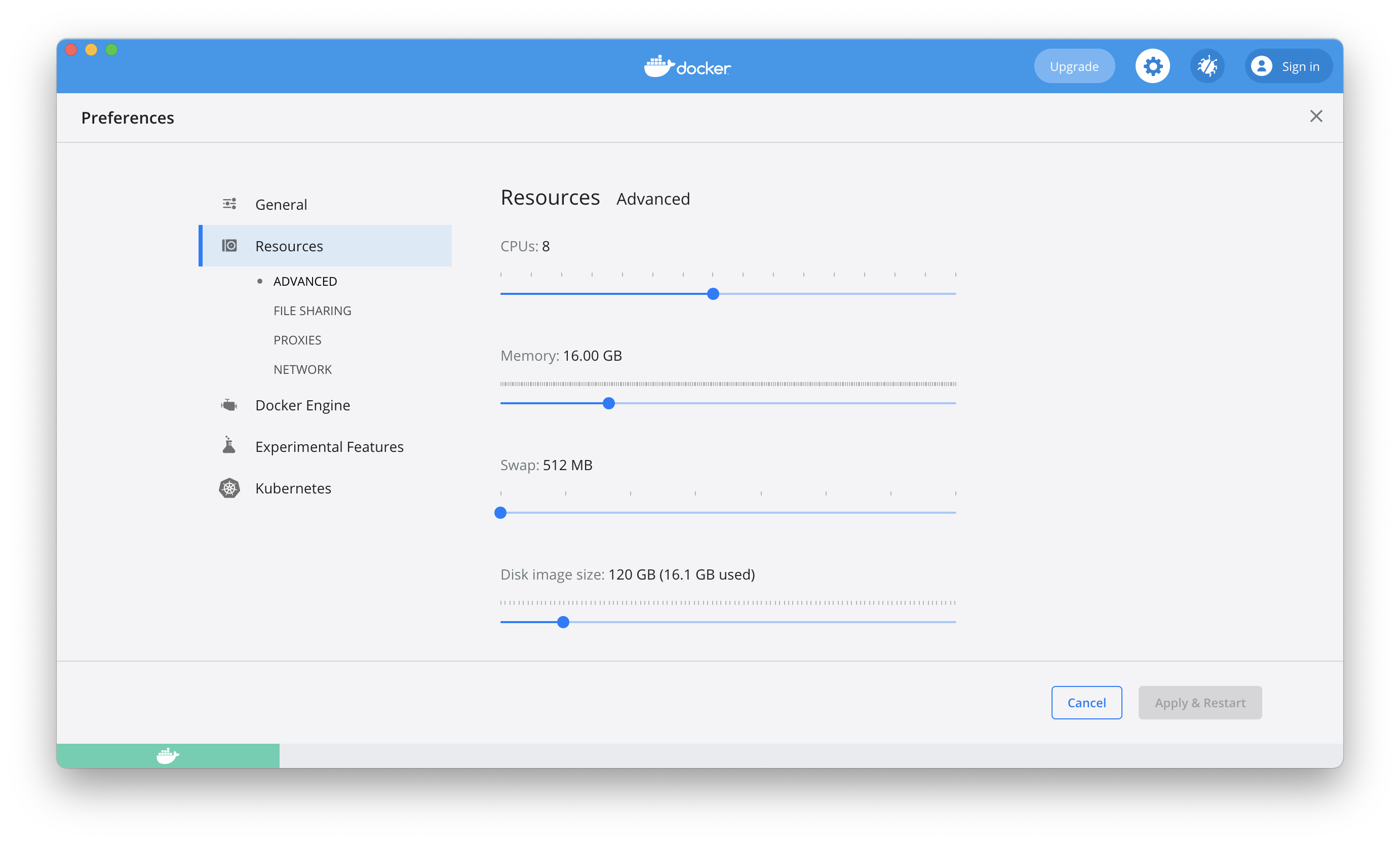
-
Clone + Build + Run
-
Create a GitHub personal access token per these instructions.
- For scopes, all you need is the
repogroup. - Keep the personal access token in something like 1Password.
- For scopes, all you need is the
-
Clone:
mkdir -p ~/git && cd ~/git git clone https://github.com/realismlabs/dataland git clone https://github.com/realismlabs/dataland-infra git clone https://github.com/realismlabs/dataland-engineering-handbook- When asked for a username, use your GitHub username.
- When asked for a password, use your personal access token, not your GitHub account password.
-
cd into dataland repo:
cd ~/git/dataland -
Build and run:
just setup -
Go to https://app.dataland.land - if everything works then the setup is complete.
VSCode
-
Install VSCode: https://code.visualstudio.com/
-
Go to Extensions and search for
@recommended. Install all the Workspace Recommendations.- See here for details.
-
Bring up the Command Palette (
Shift+Command+P) and run:Shell Command: Install 'code' command in PATH -
Open the Dataland repo in VSCode:
code ~/git/dataland -
Check that the Rust extension is working. Bring up Quick Open (
Command+P) and open:dataland-server/main.rsClicking through symbols (
Command+Click) to their definition sites should work.
Dev reset
If you pull from main and run into problems with your local instance of Dataland,
you can get a fresh working instance by running:
just reset-all
Dev workflows
Account and workspace creation
- Go to https://app.dataland.land/signup
- Go through the Email sign up flow (not Google/GitHub/OAuth)
- Go to Mailslurper hosted on http://localhost:4436 to verify your email
- Create a workspace - this automatically creates:
- A Workspace in the Orchestration Service
- A Database in the Database Service
- A Repo in the Logic Service
- A History Database in the History Service
Loading test data
To load TPC-H tables into a Dataland database:
just db-ls
# replace with real database uuid
just tpch-run-pipeline {{database_uuid}}
# if you've already done `run-tpch-pipeline` before, you don't need to re-generate the data
just tpch-import {{database_uuid}}
To get rid of the TPC-H tables:
just tpch-drop {{database_uuid}}
Frontend development
Usual iteration workflow:
cd web/dataland-app
npm run dev
This will run webpack-dev-server on https://dev-app.dataland.land.
For a full production/release build, you can run npm run build which will run webpack and emit the output files
to web/dataland-app/build. The nginx container as defined in docker-compose.yaml will serve the release assets
on https://app.dataland.land.
If you make changes to any of the libraries (dataland-api, dataland-sdk, dataland-wasm)
you need to explicitly rebuild them in order for webpack (i.e. npm run dev) to incorporate the changes
into the bundle:
# Maybe replace with `dataland-sdk`, etc.
cd web/dataland-api
npm run build
# Or if you want to just use one command that always works but is slower
just build-web
If you make changes to any of the protobuf definitions in the top-level proto directory, you need to explicitly
run the codegen process to update the dataland-api library:
just build-api
# Or if you want to directly propagate the changes all the way through in one go
just build-api build-web
Big tables are slow to load?
In the development builds, we activate several middlewares which will inspect the entire Redux state tree after every action that gets dispatched. These middlewares are very helpful for catching bugs.
But for big tables like TPC-H customer or part (150K rows and 200K rows respectively),
the data itself is part of the Redux state tree, so iterating through the entire state tree
becomes very expensive.
In production builds, webpack strips out the code which adds these middlewares, so production should continue to be fast. You can always verify that this remains true by checking https://app.dataland.land.
Backend development
// TODO(hzuo)
Principles & practices
Frontend philosophy
The frontend is about iterating as quickly as possible. Because of (1) the impossibility of nailing the perfect UI upfront and (2) the extreme speed at which new features are added and previous ones evolved, frontends are fundamentally dynamic. The best designs are ones that honor that fundamental dynamism, and are almost always designs that allow for the fastest iteration.
The key to designs that allow for fast iteration is that they maintain flexibility and defer abstraction. Abstractions lock you in to some particular way of doing things. The wrong ones will have to be immediately undone or redone during future iteration, and become a tax rather than leverage. Given the fundamental dynamism, it's very hard to predict which abstractions are right and wrong. Only after seeing evidence that a particular abstraction will provide enduring leverage should it be put into place.
The frontend mantra is: Resist the urge to abstract.
Here are is an alternate articulation of this idea from Dan Abramov (talk + post):
- https://www.deconstructconf.com/2019/dan-abramov-the-wet-codebase
- https://overreacted.io/goodbye-clean-code/
Data structures first
A Recipe
A recipe for writing simple, maintainable, robust code:
-
Think about the program you're trying to write as a state machine.
-
Articulate the actual state space of the program.
-
Encode the state space into your data structures as restrictively as possible.
- This often involves the use of algebraic data types.
-
Simply write the state transition functions.
- In a statically-typed language, provided that you've encoded the state space as restrictively as possible, the code should be obvious and there should really only be one way to write the code.1
As articulated by others
Linus Torvalds:
git actually has a simple design, with stable and reasonably well-documented data structures. In fact, I'm a huge proponent of designing your code around the data, rather than the other way around, and I think it's one of the reasons git has been fairly successful.
I will, in fact, claim that the difference between a bad programmer and a good one is whether he considers his code or his data structures more important. Bad programmers worry about the code. Good programmers worry about data structures and their relationships.
Eric Raymond:
Fold knowledge into data, so program logic can be stupid and robust.
Data is more tractable than program logic. It follows that where you see a choice between complexity in data structures and complexity in code, choose the former. More: in evolving a design, you should actively seek ways to shift complexity from code to data.
Rob Pike:
Data dominates. If you’ve chosen the right data structures and organized things well, the algorithms will almost always be self-evident. Data structures, not algorithms, are central to programming.
This idea of restricting the number of different ways code can be written and relying on the type system to prove that the code stays on one of these paths is similar to the idea of parametricity.
Guides
A Guide is an curated walkthrough of an external concept or technology written collectively by people who've gone on the journey from zero to achieving understanding. The goal is to accelerate that journey for future generations.
Guides are usually structured as sequenced "course" of external resources along with some light framing and editorialization.
Original concepts, concepts we invented ourselves or concepts that are particular to Dataland, are usually structured as RFCs.
Rust Guide
The Rust Book
Almost everyone learns Rust by reading The Rust Book, affectionately known as "the book" inside the Rust community:
https://doc.rust-lang.org/book/
I also found it helpful to jump through Rust By Example as a companion text:
https://doc.rust-lang.org/rust-by-example/
It's a bunch of code examples that are designed to illustrate language features. The examples are commented with some light exposition, so it could be an alternative to parts of The Rust Book if you're short on time.
More on Ownership
To get a deeper understanding of ownership, check out the Nomicon:
https://doc.rust-lang.org/nomicon/ownership.html
In particular, the subsection on Aliasing gives the formal definition of what it means to alias in Rust:
Variables and pointers alias if they refer to overlapping regions of memory.
Thus when working with the borrow checker, the programmer is fundamentally reasoning about memory regions.
This explains why &mut arr and &mut arr[2] are aliases, even though they're syntactically borrowing
different objects.
Here's another post that helps motivate why shared mutability is problematic:
https://manishearth.github.io/blog/2015/05/17/the-problem-with-shared-mutability/
Async Rust
Since we're building high concurrency network services in Rust, we heavily use "Async Rust" which is a collection of language features + ecosystem libraries for dealing with asynchronous I/O.
Async Rust is not covered in The Rust Book, so instead I've collected a series of resources I found to be most helpful:
-
Start by watching Withoutboats's overview of Async Rust.
-
Then watch this video by Jon Gjengset on the semantics of async/await.
-
Skim through the Async Rust Book.
-
Go through the Tokio tutorial.
-
Check that you're able to completely understand the mini-redis codebase.
-
Read Alice Ryhl's blog post on implementing Actors with Tokio, which I've found to be a dominant pattern in practice. For example, all the handlers in mini-redis are instances of this pattern. This post is also a good mental model for how channels are used in practice.
Supplemental material:
- Jon Gjengset's video on Async Rust (less up-to-date but more in-depth than the one above)
- Jon Gjengset's video on pinning
- Eliza Weisman's talk on tokio-tracing
Other resources
- Rust Container Cheat Sheet
- Rust Language Cheat Sheet
- Rust RFC Book
- Rust subreddit
- Rustacean Station podcast
- Jon Gjengset's YouTube channel
- This Week in Rust email newsletter
- Tokio Discord server
- Rust Fuzz Book
- Rust Performance Book
React & Redux
React practical tutorial: https://reactjs.org/tutorial/tutorial.html
React guide to main concepts: https://reactjs.org/docs/hello-world.html
React Hooks: https://reactjs.org/docs/hooks-intro.html
Dan Abramov's React deep dive: https://overreacted.io/react-as-a-ui-runtime/
Dan Abramov's useEffect deep dive: https://overreacted.io/a-complete-guide-to-useeffect/
Redux principles: https://redux.js.org/understanding/thinking-in-redux/three-principles
Distributed state machines
Jay Kreps on state machine replication: https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying
Schneider on state machine replication: https://www.cs.cornell.edu/fbs/publications/SMSurvey.pdf
Lamport on time, clocks, and ordering: https://lamport.azurewebsites.net/pubs/time-clocks.pdf
Protocol Buffers
Language Guide (proto3): https://developers.google.com/protocol-buffers/docs/proto3
Encoding: https://developers.google.com/protocol-buffers/docs/encoding
Apache Arrow
RFCs
RFC 001 - The History Database
- Feature Name: The History Database
- Start Date: 2021-09-16
- RFC PR: realismlabs/dataland-engineering-handbook#3
- Author: Aarash Heydari
Summary
Introduce the history database, enabling analytical SQL queries against past points in time of a database. For each tenant database in db-server, a copy of the history of that database is persisted in a separate "history database". The primary APIs of the history database execute read-only SQL queries with an extra parameter tquery, having time-machine semantics: "Execute the SQL query against the past state of the base database at time tquery".
Motivation
A number of features require, in some way, the persistence of past states of a database.
- Changelog / "Diff" view of a database
- Figma Link
- The goal is to provide an experience similar to Git's commit history, but for edits to a database.
- There are primarily two modes of changes:
- Schema-level changes, including adding/removing/changing columns or tables.
- The user should be able to easily query the history of schema changes.
- Row-level changes.
- The user should be able to easily query the history of changes to a particular row.
- Solely leveraging the transaction log within db-server for the above would be doable (by dynamically playing back a transaction log to resolve the state of an individual object at a given time), but this approach falls apart if we want to do any kind of analytical query on the past, or query related data.
- "Consistent view of the world" for async workers
-
Workers consume and act upon DB changes/events by listening to a FIFO queue.
-
Workers want to be able to run SQL queries against their source DB in response to events. Their predictable use-cases include the following:
- What was the pre-/post-image of a row before/after a transaction?
- What was the state of some other row related to the updated row (potentially from a different table)
- Arbitrary analytical queries, such as averaging over a column or doing complex joins.
-
But, reading directly from the source DB suffers from a "reading from the future" problem.
The 'reading from the future' problem
Suppose we have 3 events:
- Insert Row 1 into Table T1 with {a: 1, b: 2}
- Update Row 1 with {b: 5}
- Drop Table T1
A worker may be responding to event (2) here and be interested in the pre-image of Row 1 before event (2). However, if the workers query db-server directly, they will find that the table T1 has already been dropped, such that the data that the worker needs no longer exists.
To ensure workers can always query their relevant data, they require the ability to query a "frozen in time" past version of the DB corresponding to the timestamp of the event that they are responding to.
- Providing time-machine query-ability to databases in general is powerful and may be useful as a standalone feature.
Guide-level explanation
What does it mean to query a frozen-in-time version of a database?
-
If a row has a particular cell value changed at tx, then querying the row with query timestamp tx-1 should yield the old value, and querying with tx+1 should yield the new value.
-
If a table is renamed from
my_tabletomy_table_2at time tx, then loadingmy_tablewith timestamp tx-1 should succeed, but loadingmy_table_2at that time should fail, and vice versa for tx+1. Dropping or creating a new table behaves similarly to the renaming case. -
Similarly, if a column is renamed (or dropped & another one is created) then loading the table with a query timestamp before the rename should yield the column under the old name, and a query timestamp after the rename should yield the column under the new name.
Relationship with Tenant Databases
Each history database mirrors one db-server tenant database, subject to the following relation:
Tables
The schema of a table can change over time. Suppose my_table is created at time tschema1, then row
insertions and deletions happen. A column is dropped at time tschema2 and then a new column is added
at tschema3.
Depending on the tquery, the columns which should be returned from SELECT * FROM my_table will differ.
To support all previous schemas of a table, the history table schema for a given table must be a super-set of all past
schemas of the table. This table shall be called the supertable of the base table. The base table and
supertable share the same table_uuid.
To provide the illusion of the desired schema at time tquery, subqueries which select the desired subset of the supertable schema are used.
Schema History
Each time the schema of a base table changes, a new row is added to the Schema History table, which has the following structure:
-- Each time a schema change to any table within db-server occurs,
-- a new row is added to this table.
create table _history_catalog.schema_history (
-- The UUID of the table / supertable which were altered.
table_uuid uuid not null,
-- The user-assigned name of the table.
table_name text not null,
-- The logical timestamp of this schema change.
logical_timestamp bigint not null unique,
-- A struct-ified representation of a schema, including column UUIDs/names/data-types.
-- Null for a table which has been dropped (or renamed).
schema_descriptor bytea
);
Where schema_descriptor is actually the TableDescriptor proto message from rtdp.proto. It resembles the following:
{
// Identifier for both the base table and the supertable.
"table_uuid": "xxxxx-xxxxxxxxx-xxxx",
// User-assigned name for the base table.
"table_name": "my_table_name",
// The schema of the table at this point in time.
"column_descriptors": [
// Identifier for both the base column and the supercolumn.
"column_uuid": "xxxxx-xxxxxxxxx-xxxx",
// User-assigned name for the base column.
"column_name": "my_column_name",
"data_type": "<enum>", // the SQL type of the column
"is_nullable": true,
/// The position of the column in the total ordering across all of the table's columns,
/// specified as a lexicographic key.
/// The synthetic key and ordinal key columns should always come first and second.
"column_ordinal_key": "<key>",
]
}
To fetch the relevant schema for a given table at a given timestamp, the following SQL can be used:
SELECT table_uuid, schema_descriptor from _history_catalog.schema_history
WHERE table_name = $1 AND logical_timestamp < $2
ORDER BY logical_timestamp DESC LIMIT 1
Columns
All columns which ever existed in the base table are associated with a "supercolumn" in the supertable. Supercolumns are never dropped, because even if the base column is dropped, queries under past timestamps must still see the column and its values.
Supercolumns are created whenever base columns are created or have their data type changed. They are NOT created when base columns are renamed.
The supercolumns are named according to the pattern <column_uuid>-<logical_timestamp of column creation>.
Including the logical timestamp in the supercolumn name assists in cases of data-type changes to the base table schema. Data-type changes require the old version and new version of the column to exist side-by-side as separate supercolumns.
All supercolumns are always nullable. This is to support dropping of a column while maintaining the supercolumn.
After a base column is dropped, any subsequent row insertions should write null to the corresponding supercolumn.
Rows
- All row mutations (altering a cell value, deleting a row, inserting a new row) for a given base table all cause a new row to be inserted into the corresponding history table.
- All rows in the base database are augmented with following two reserved columns:
logical_timestamp: The logical timestamp of the base database event which triggered the history change. This is used to facilitate querying a frozen point-in-time by ignoring all items with alogical_timestampgreater than thequery_timestampof the request.is_deleted: When a base database row is deleted, a history row is inserted with this boolean set to true. This is used in conjunction withlogical_timestampto filter out rows that have already been deleted at a given tquery.
The following invariant should always be true:
The Reconstruction Invariant
The following query against the supertable of
my_tableshould always match the state of the basemy_tableas it had appeared at time$t_query.WITH ranked_by_age_within_key AS ( SELECT *, ROW_NUMBER() OVER (partition by synthetic_key order by logical_timestamp desc) AS rank_in_key FROM <table_uuid> WHERE logical_timestamp < $t_query ) SELECT -- Subset of the supertable's columns based on the schema from time $t_query <column_uuid1> as <column_name1>, <column_uuid2> as <column_name2>, ..., FROM ranked_by_age_within_key -- Only accept the newest version of every base row, and only WHERE rank_in_key = 1 and is_deleted = false
...Where ROW_NUMBER() and rank_in_key facilitate only selecting the newest version of each row,
even though many versions of that row exist in the supertable having different logical_timestamps.
NOTE:
SELECT DISTINCT ON, or other window functions may lead to a more performant version of the above query. See https://stackoverflow.com/questions/3800551/select-first-row-in-each-group-by-group
Tying it together
To load the table table_uuid_1 in the history table at time tquery:
-
First, verify that tquery is "in the past" from the perspective of the history database. Throw an error if tquery is greater than the last timestamp which was queried. (Each database tracks the last processed
logical_timestamp). -
Resolve the schema of the table from the POV of tquery using a query like
SELECT table_uuid, schema_descriptor from _history_catalog.schema_history
WHERE table_name = $1 AND logical_timestamp < $2
ORDER BY logical_timestamp DESC LIMIT 1
- The schema_descriptor will specify which columns of the supertable were relevant at the point in time tquery, leading to a query resembling the following:
WITH frozen_in_time AS ( WITH ranked_by_age_within_key AS ( SELECT *, ROW_NUMBER() OVER (partition by synthetic_key order by logical_timestamp desc) AS rank_in_key FROM <table_uuid> WHERE logical_timestamp < $t_query ) SELECT -- Subset of the supertable's columns based on the schema from time $t_query <column_uuid1> as <column_name1>, <column_uuid2> as <column_name2>, ..., FROM ranked_by_age_within_key -- Only accept the newest version of every base row, and only WHERE rank_in_key = 1 and is_deleted = false ) SELECT <arbitrary customer SQL> FROM frozen_in_time
APIs
The initial APIs query the past state of a row, or the past state of a table/schema.
service HistoryService {
// Fetch an individual row at a given point in time.
rpc FetchRow(FetchRowRequest) returns (FetchRowResponse);
// Load an entire table at a given point in time.
rpc LoadTable(LoadTableRequest) returns (LoadTableResponse);
// Get the catalog/schemas at a given point in time.
rpc GetCatalog(GetCatalogRequest) returns (GetCatalogResponse);
}
message FetchRowRequest {
// Table Identifier
bytes table_uuid = 1;
// The `primary_key` used to uniquely identify a row from the source/tenant DB.
sint64 synthetic_key = 2;
// Load the row as it appeared at this point in time.
uint64 query_timestamp = 3;
}
message FetchRowResponse {
// An ordered list of the column UUIDs in the response.
repeated bytes column_uuid_mapping = 1;
// An ordered list of the values within the row, corresponding to the column ordering above.
repeated Scalar values = 2;
}
message LoadTableRequest {
// Table Identifier
bytes table_uuid = 1;
// Load the table as it appeared at this point in time.
uint64 query_timestamp = 2;
}
message LoadTableResponse {
// An ordered list of the column UUIDs in the response.
repeated bytes column_uuid_mapping = 1;
// An ordered list of the values within the row, corresponding to the column ordering above.
repeated Scalar values = 2;
}
message GetCatalogRequest {
// View the catalog schemas as they appeared at this point in time.
uint64 query_timestamp = 1;
}
message GetCatalogResponse {
// The name/uuid/columns of all tables.
repeated TableDescriptor table_descriptors = 1;
}
Reference-level explanation
Each workspace's history database includes the following pieces of state:
_history_catalog.schema_history-- A table which tracks all changes to schemas of all tables within the database._supertables.XXXXXX-- A schema which includes one supertable (identified by thetable_uuid) for each table that has ever existed in the base database._history_metadata.last_logical_timestamp-- A table with 1 row which always stores (and atomically updates) the most recent logical timestamp which completed processing. This assists in rejecting queries that try to read the future.
CreateDatabase handler (New workspace creation)
db-server runs tenant-db-migrations to bootstrap some resources when a new workspace is created.
The history database will do the same.
- Initialize the
_history_catalog.schema_historytable, the_history_catalog.last_logical_timestamptable, and the_supertablesschema.
-- 1 `schemas` table per workspace
create schema _history_catalog;
-- 1 supertable per base table
create schema _supertables;
-- Each time a schema change to any table within the base database occurs,
-- a new row is added to this table.
create table _history_catalog.schema_history (
-- The UUID of the table / supertable which were altered.
table_uuid uuid not null,
-- The user-assigned name of the table.
table_name text not null,
-- The logical timestamp of this schema change.
logical_timestamp bigint not null unique,
-- A struct-ified representation of a schema, including column UUIDs/names/data-types.
-- Null for a table which has been dropped (or renamed).
schema_descriptor bytea
);
-- This table just stores 1 row which is atomically updated every time a new event from the base table is processed
create table _history_catalog.last_logical_timestamp (
logical_timestamp bigint not null unique
)
Supertables - Row Mutations
Consider the following example of how inserting/updating/deleting rows and changing the schema would affect the supertable.
Table State 1:
| synthetic_key | column1 |
|---|---|
| id1 | value1 |
Supertable state 1:
| synthetic_key | <column1_uuid>-t1 | is_deleted | logical_timestamp |
|---|---|---|---|
| id1 | value1 | f | 1 |
Table State 2: insert a row
| synthetic_key | column1 |
|---|---|
| id1 | value1 |
| id2 | value2 |
Supertable state 2:
| synthetic_key | <column1_uuid>-t1 | is_deleted | logical_timestamp |
|---|---|---|---|
| id1 | value1 | f | 1 |
| id2 | value2 | f | 2 |
Table State 3: edit value2
| synthetic_key | column1 |
|---|---|
| id1 | value1 |
| id2 | value2_prime |
Supertable state 3: There are now two rows corresponding to synthetic key 2 with 2 different logical timestamps!
| synthetic_key | <column1_uuid>-t1 | is_deleted | logical_timestamp |
|---|---|---|---|
| id1 | value1 | f | 1 |
| id2 | value2 | f | 2 |
| id2 | value2_prime | f | 3 |
Table State 4: Delete the row of id1
| synthetic_key | column1 |
|---|---|
| id2 | value2_prime |
Supertable State 4: The deletion causes the insertion of a new row with is_deleted = true
| synthetic_key | <column1_uuid>-t1 | is_deleted | logical_timestamp |
|---|---|---|---|
| id1 | value1 | f | 1 |
| id2 | value2 | f | 2 |
| id2 | value2_prime | f | 3 |
| id1 | null | t | 4 |
RowMutation - Insert handler
Straightforwardly insert a new row into the supertable using the synthetic key from the base table's item,
copying the data over, with is_deleted=false and logical_timestamp set.
The new row will be the first and only entry corresponding to the given synthetic key.
RowMutation - Update handler
The row update doesn't fully specify the post-update attributes of the row. Therefore, this handler will need to query the most recent state of the row identified by the synthetic key (before the update), copy-over the values from the latest version, apply the update, and write-back the new fully-specified item to the supertable. There will now be more than one row in the supertable corresponding to this synthetic key, and either one could be served to the user depending on tquery.
RowMutation - Delete handler
Similarly to the update case, deletions will insert a new row to the supertable having is_deleted=true.
If a query requests a point in time after the deletion, then the newest row corresponding to the synthetic key
will be this 'deleted' row, which would be filtered out of the results set.
Unlike the Update case, it's not essential to copy-over the row's previous values into the new deletion row,
because this row only exists for the purpose of being filtered out based on its timestamp - the values are never read.
It is acceptable to use null for all values other than synthetic key and the reserved Dataland fields.
Supertables and Schema History - Schema changes
Table State 1:
| synthetic_key | column1 (BIGINT) |
|---|---|
| id1 | 1 |
Supertable State 1:
| synthetic_key | <column1_uuid>-t1 (BIGINT) | is_deleted | logical_timestamp |
|---|---|---|---|
| id1 | 1 | f | t1 |
Schema History State 1:
| table_uuid | table_name | logical_timestamp | schema_descriptor |
|---|---|---|---|
| <table_uuid_1> | my_table | t1 | {"column1": { "type": "BIGINT", "supercolumn_name": "<column1_uuid>-t1" }} |
Table State 2: Add column2 with default value 2 and type TEXT.
| synthetic_key | column1 (BIGINT) | column2 (TEXT) |
|---|---|---|
| id1 | 1 | 2 |
Supertable State 2: Add the column.
| synthetic_key | <column1_uuid>-t1 (BIGINT) | <column2_uuid>-t2 (TEXT) | is_deleted | logical_timestamp |
|---|---|---|---|---|
| id1 | 1 | 2 | f | t1 |
Schema History State 2: Add a new schema including the new column.
| table_uuid | table_name | logical_timestamp | schema_descriptor |
|---|---|---|---|
| <table_uuid_1> | my_table | t1 | {"column1": { "type": "BIGINT", "supercolumn_name": "<column1_uuid>-t1" }} |
| <table_uuid_1> | my_table | t2 | {"column1": { "type": "BIGINT", "supercolumn_name": "<column1_uuid>-t1" }, "column2": { "type": "TEXT", "supercolumn_name": "<column2_uuid>-t2" }} |
Table State 3: drop column1
| synthetic_key | column2 (TEXT) |
|---|---|
| id1 | 2 |
Supertable State 3: No-op against the supertable.
Schema History State 3: Add a new schema which doesn't include the dropped column1.
| table_uuid | table_name | logical_timestamp | schema_descriptor |
|---|---|---|---|
| <table_uuid_1> | my_table | t1 | {"column1": { "type": "BIGINT", "supercolumn_name": "<column1_uuid>-t1" }} |
| <table_uuid_1> | my_table | t2 | {"column1": { "type": "BIGINT", "supercolumn_name": "<column1_uuid>-t1" }, "column2": { "type": "TEXT", "supercolumn_name": "<column2_uuid>-t2" }} |
| <table_uuid_1> | my_table | t3 | {"column2": { "type": "TEXT", "supercolumn_name": "<column2_uuid>-t2" }} |
Table State 4: Change the type of column2 to BIGINT.
| synthetic_key | column2 (BIGINT) |
|---|---|
| id1 | 2 |
Supertable State 4: Add a new supertable column corresponding to the new type, preserving the ability to query against the "old" type.
| synthetic_key | <column1_uuid>-t1 (BIGINT) | <column2_uuid>-t2 (TEXT) | <column2_uuid>-t4 (BIGINT) | is_deleted | logical_timestamp |
|---|---|---|---|---|---|
| id1 | 1 | 2 | 2 | f | t1 |
Schema History State 4: Add a new schema which changes the type and supercolumn_name of column2.
| table_uuid | table_name | logical_timestamp | schema_descriptor |
|---|---|---|---|
| <table_uuid_1> | my_table | t1 | {"column1": { "type": "BIGINT", "supercolumn_name": "<column1_uuid>-t1" }} |
| <table_uuid_1> | my_table | t2 | {"column1": { "type": "BIGINT", "supercolumn_name": "<column1_uuid>-t1" }, "column2": { "type": "TEXT", "supercolumn_name": "<column2_uuid>-t2" }} |
| <table_uuid_1> | my_table | t3 | {"column2": { "type": "TEXT", "supercolumn_name": "<column2_uuid>-t2" }} |
| <table_uuid_1> | my_table | t4 | {"column2": { "type": "BIGINT", "supercolumn_name": "<column2_uuid>-t4" }} |
Table State 5: Rename column2 to mycolumn2.
| synthetic_key | mycolumn2 (BIGINT) |
|---|---|
| id1 | 2 |
Supertable State 5: No-op against the supertable.
Schema History State 5: Add a new schema which changes the symbol column2 without changing the supercolumn_name.
| table_uuid | table_name | logical_timestamp | schema_descriptor |
|---|---|---|---|
| <table_uuid_1> | my_table | t1 | {"column1": { "type": "BIGINT", "supercolumn_name": "<column1_uuid>-t1" }} |
| <table_uuid_1> | my_table | t2 | {"column1": { "type": "BIGINT", "supercolumn_name": "<column1_uuid>-t1" }, "column2": { "type": "TEXT", "supercolumn_name": "<column2_uuid>-t2" }} |
| <table_uuid_1> | my_table | t3 | {"column2": { "type": "TEXT", "supercolumn_name": "<column2_uuid>-t2" }} |
| <table_uuid_1> | my_table | t4 | {"column2": { "type": "BIGINT", "supercolumn_name": "<column2_uuid>-t4" }} |
| <table_uuid_1> | my_table | t5 | {"mycolumn2": { "type": "BIGINT", "supercolumn_name": "<column2_uuid>-t4" }} |
From this point, dropping the base table would be a no-op against the supertable, and would insert one last entry
into the schema history, having null schema_descriptor to indicate that the table no longer exists:
| table_uuid | table_name | logical_timestamp | schema_descriptor |
|---|---|---|---|
| ... | ... | ... | ... |
| <table_uuid_1> | my_table | t6 | null |
AddColumn handler
- Supertable: Add a new column of matching type into the supertable, with the name
<new_column_uuid>-<logical_timestamp>. - Schema History: Find the most recent schema history for the table. Insert a new row which copies all values, only modifying the schema_descriptor by appending a key-value mapping for the new column.
DropColumn handler
- Supertable: No-op.
- Schema History: Find the most recent schema history for the table. Insert a new row which copies all values, only modifying the schema_descriptor by removing a key-value mapping for the dropped column.
RenameColumn handler
- Supertable: No-op, because the supercolumn remains the same.
- Schema History: Find the most recent schema history for the table. Insert a new row which copies all values, only modifying the schema_descriptor by editing the key of the key-value mapping for the renamed column.
ChangeColumnDataType handler
- Supertable: Add a new column corresponding to the new data type with default=Null. Loop over the rows which currently exist in the base table and update those rows in the supertable by setting the value of the new column based on the old value for that row and the provided casting function.
- Schema History: Find the most recent schema history for the table. Insert a new row which copies all values, only
modifying the schema_descriptor by editing the
typeandsupercolumn_namefor the altered column.
ChangeColumnIsNullable handler
-
Supertable: No-op for the supertable. The supertable always allows all columns to be nullable, so that it can behave correctly if a column is dropped -- when new insertions occur, they should write null to the no-longer-existing column. Because the supertable's data comes from the base table, the values sent to a NOT NULL column of the base table should always produce non-null values in the supertable.
-
Schema History: In order for GetCatalog to return a correct
table_descriptor, we still need to insert a new row into theschema_historytable.
ReorderColumn handler
- Supertable: Obvious no-op.
- Schema History: Because the
table_descriptorof the base table has changed, we must insert a new entry into theschema_historytable to record the new column order.
CreateTable handler
- Supertable: Create a new supertable, using the naming scheme
<column_uuid>-<logical_timestamp>for each column, with three reserved columns:synthetic_key,is_deleted, andlogical_timestamp. - Schema History: Insert a new row into the
schema_historytable corresponding to the initial schema of the table.
DropTable handler
Supertable: No-op, because all of the data must remain queryable for query timestamps before the drop time.
Schema History: Newer-timestamped attempts to query the table should fail. To facilitate this, a new row is inserted
into schema_history marking the table name/uuid as deleted, by setting the schema_descriptor to null.
RenameTable handler
Supertable: No-op because none of the underlying data changes. The supertable is actually named using the table_uuid.
The schema_history needs to mark the symbol name of the old table as now-invalid, and the new name as valid.
Therefore, two insertions are done: One which looks similar to dropping the old table (marking the
schema_descriptor as null), and another which looks similar to creating a new table with the new name.
| table_uuid | table_name | logical_timestamp | schema_descriptor |
|---|---|---|---|
| ... | ... | ... | ... |
| <table_uuid_1> | old_table_name | t_rename | null |
| <table_uuid_1> | new_table_name | t_rename | <current_table_schema> |
Compaction
A general piece of SQL wisdom is to avoid "infinitely-growing tables", because even the simplest queries eventually become intractable if they don't perfectly leverage indices. Supertables do grow infinitely, because even deletes in the base table cause insertions in the supertable. This section will describe a compaction scheme which maintains invariants but 'forgets' the past up until a new "beginning of time" tpurge, a timestamp after which the Reconstruction Invariant will still be honored.
Can't simply drop all rows with logical timestamp less than tpurge
Imagine the majority of the rows in the base table change every day, but one row was inserted at the beginning of time and never altered. We can never drop this particular row, because doing so would violate the reconstruction invariant: The row which was inserted at the beginning of time still exists in the base table.
Rather than blindly dropping all data before the purge timestamp, the following query will delete the maximum number of rows while preserving the Reconstruction Invariant for any time after tpurge.
WITH to_be_deleted AS (
WITH ranked_by_age_within_key AS (
SELECT synthetic_key, logical_timestamp, ROW_NUMBER() OVER (partition by synthetic_key
order by logical_timestamp desc) AS rank_in_key
FROM <table_uuid>
-- Only consider candidates from before the purge timestamp
WHERE logical_timestamp < $purge_timestamp
)
SELECT synthetic_key, logical_timestamp
FROM ranked_by_age_within_key
WHERE
-- "delete everything except the newest version of the item as of the purge time"
rank_in_key > 1
-- If the item is fully deleted by this time, it's safe to drop it completely.
OR is_deleted = true
)
DELETE FROM <table_uuid> WHERE (synthetic_key, logical_timestamp) IN to_be_deleted;
Rationale and alternatives
Why store semi-redundant copies of data every time the data is updated?
It's true that the storage cost of this scheme is high, and would grow unbounded until compaction. However, semi-redundant copies of data is the only way to offer a fully consistent view of the past with rich SQL query-ability.
Using a transaction-log-only, or only storing incremental changes rather than fully copies, could confer the ability to do point queries for the past state of an individual row item (by dynamically replaying the transaction log for a given synthetic key). But, running a SQL query against a consistent past point-in-time is completely infeasible.
Because Workers require the richer feature-set of analytical SQL queries against the past state of the world, we are forced to swallow the cost of semi-redundant duplicated data. However, truncation and exporting old data to cold storage could alleviate this problem.
Postgres, DuckDB, Snowflake, or another DB?
Based on the following analysis, the decision was made to use DuckDB.
-
Postgres
- Pros
- Well-understood with good async Rust library
- Generally great feature set
- Cons
- Row-based memory layout makes queries like ROW_NUMBER() OVER(partition by...) slow
- Shared physical resources within a Postgres cluster
- Pros
-
DuckDB
- Pros
- Columnar format and vectorized queries should be conducive to our query access pattern.
- Embedded in-process runtime -- low overhead / no network calls / very high performance
- "Full SQL support", uses PostgresSQL parser, with great Parquet integration
- Cons
- Relatively young technology (2018) & <200 users of the duckdb-rs crate
- Sharing physical resources of the
history-serverdocker container disk (but 1 separate storage file per tenant database)
- Pros
-
Snowflake
- Pros
- Infinite S3 distributed storage warehouse, scalable compute with EC2
- Columnar format
- Cons
- Monetarily expensive! $$$
- Pay for compute upon every insertion or query -- the warehouse would rarely have a chance to shut down.
- Substantial external dependencies
- Network traffic latency
- Not designed for individual insertions, much prefers bulk insertion / Often delay between write and readability.
- Monetarily expensive! $$$
- Pros
Future possibilities
Rich & Queryable Database Audit Logs
db-server currently stores a transaction log of all base tables. But, a naked transaction can only confer a limited amount of information: It does not store the pre-image of a change, nor would it allow for running analytical queries at a prior point in time.
Suppose a user browses the transaction log and finds a transaction they didn't expect. Using the history database, they can run arbitrary queries on the state of the database at the time of the unexpected transaction.
Export parquet to S3 - Backups & Cold Tier
As aforementioned, infinitely-growing SQL tables will always eventually become a CPU/memory/performance issue. To address this, one could imagine moving truncated data to S3 rather than fully destroying it. It could then be loaded on-demand as needed. DuckDB has great support for parquet integration, which makes exporting and loading data easy.
This provides value in two ways:
-
Solve the infinite data growth problem by moving pruned parts of the history database to cold tier. This enables compaction without sacrificing queryability of old data.
-
Materialize point-in-time backups for all tenant DBs. The history database can be used to generate arbitrary point-in-time backups in parquet format, which the user can keep for compliance purposes or ransomware protection.
RFC 002 - The Real-Time Data Protocol
Lexicographic Keys
References
1 Matula and Kornerup 1983 - An order-preserving finite binary encoding of the rationals
http://www.acsel-lab.com/arithmetic/arith6/papers/ARITH6_Matula_Kornerup.pdf
2 Kornerup and Matula 1995 - LCF: A Lexicographic Binary Representation of the Rationals
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.108.5117&rep=rep1&type=pdf
3 Z85 spec
https://rfc.zeromq.org/spec/32/